The application centres around log entries. Every time you train, you create a log entry. The log entry stores the time when the training session was started and completed. The log entry contains a collection of sets. A set consists of one or more repetitions of a single exercise at a uniform intensity.
All other entities in the domain model projects out from this central requirement.
A set consists of an exercise and repetitions. Exercises are categorised by muscle groups. Hence there are exercises and categories.
Sequences of sets are organised into a routine, which serve as a template for a training log.
- Categories – A list of body muscle groups, which is used to classify exercises.
- Exercises – A list of body activities for improved strength, conditioning, agility or endurance.
- Repetitions – The number of times a complete motion of an exercise has to be executed.
- Sets – A group of continuous, consecutive repetitions of the same exercise.
- Routines – A collection of several sets of one or more exercises, to be performed sequentially.
- Training Logs – A record of the date, time and duration when a particular routine was performed.
Categories
Categories muscle groups in the body. This list is static and has no user-interface elements to modify its contents. It is created when the database for the application is initially created, and remains unchanged throughout its lifetime. The full list of categories included in Valknut is given below.
- Abdominals
- Abductors
- Adductors
- Biceps
- Body
- Calves
- Chest
- Forearms
- Glutes
- Hamstrings
- Lats
- Lower Back
- Middle Back
- Neck
- Quadriceps
- Shoulders
- Traps
- Triceps
Some fitness-training literature uses the term category to describe the the primary goal of the exercise. These systems consist of strength, hypertrophy, endurance, flexibility, balance, agility, speed, power and accuracy. This aspect is (partially) fulfilled in Valknut by the exercise property called type.
Exercises
An exercise has a name, a category and a type. Categories and types have been explained above. New exercises can be created at any time, but to delete an exercise, its entries from the routines and log entries must be remove manually beforehand.
Routines
A routine is a sequence template. It describes the desired initial structure of a training session as a series of exercises to be performed, the number of sets for each exercise, the intensity of the set, and the number of repetitions to be performed. Weights and repetitions for each set can differ in order to create straight, pyramid or reverse-pyramid patterns.
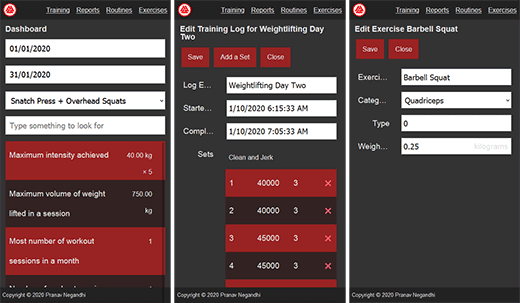
Training Log
The training log is a memo of the name of the workout, the sequence, intensity and repetitions of its component exercises, the date and time when it was performed and the duration it took.
Routines serve as a template for a log entry. When a new entry is added to the training log, the sequence of exercises, the number of sets, the intensity of the exercise and the number of repetitions are copied from a previously created routine. But log entries do not retain any association with the routine. If the routine is modified after a log entry has been created, its modifications do not reflect on the log entry. Conversely, the sequence of exercises and sets in a log entry can be altered without affecting the routine from which it was created.